Is Performance a Power Law?
Meaning, Metrics, and Misattribution

Years ago, I proposed a performance evaluation framework at a large tech company. I had crafted a rigorous yet parsimonious behavioral competency model that was grounded in the literature but also practical enough to apply across the business. It was elegant. It was crisp.
And they nearly laughed me out of the room.
“Why would we care about what someone is good at? We care about what they deliver.”
I’m embellishing only slightly when I say I felt the earth shake beneath my feet. Is everything I know about performance wrong? What have I been measuring my whole career?
At the time, I chalked it up to a translation issue: academics versus operators, theory versus practice. What I didn’t realize was the implicit orthodoxy about the nature of performance was already shifting.
Gradually, it became prevailing wisdom — almost undisputed — that performance is inherently a power-law-distributed output.
You hear it all the time now, just stated as a matter of fact: Top performers are 10x. 20% of the company does 80% of the work. We should allocate outsized rewards for outsized impact.
It’s not that these statements are patently false. But something never sat quite right with me: When we say performance follows a power law, what do we mean by performance, exactly? Are we talking about the distribution of outputs? Or of human capability itself?
That distinction is subtle, seemingly semantic, but it’s more seismic than you might think.
How power law became orthodoxy
As far as I can tell, it all started in 2012 with a paper in the Journal of Personnel Psychology by Ernest O’Boyle and Herman Aguinis1 that made a genuinely shocking claim: unlike an arguable majority of human properties2 — from intelligence to resting heart rate to patience to parallel parking ability — job performance conforms not to a normal, Gaussian, bell-shaped distribution but rather a power law, or Paretian distribution. In other words, they said, instead of most people clustering around average and few at the very high and low ends, the vast majority are at the low end of the scale, and a very small number several standard deviations above.
To folks outside of statistics or I/O psychology, this issue may seem abstract and, frankly, inconsequential. But it’s hard to overstate how radical this assertion was. Performance is the outcome of interest for a huge swath of the research in organizational psychology, and many of our commonly-used statistical methods operate under the assumption that the variables we analyze are normally distributed. Basically, if true, O’Boyle & Aguinis’s assertion would throw into question nearly every meaningful finding on the subject of job performance in the history of the field.
I read it, raised an eyebrow, and moved on.
But before long, this very idea had crept out of academic journals and into mainstream HR. Consulting firms, major institutions, and influential thought leaders now talk about the power law phenomenon not just as a statistical observation but as a default operating principle about the nature of performance and — perhaps of even greater consequence — how we link performance to compensation.
For me, the puzzling part of the O’Boyle & Aguinis article was definitional, not statistical. The word “performance” appears 248 times in that paper. Three of those times, it says “performance output” — and that’s what they are actually measuring. Their conclusions rest on a series of studies using very specific and eccentric performance outcomes. They count, for example, number of Oscar nominations, political reelections, top-tier research publications, and a smorgasbord of sports stats: home runs, strikeouts, goalie saves, rushing yards, touchdown receptions, sacks.
But Oscar nominations are not the same as cinematic achievement. Top-tier publications are not the same as research quality. (I said what I said.) They are proxies and downstream outcomes of performance. And — critically! — they are all counts, profoundly shaped by opportunity, visibility, sampling, range restriction, and time. The nature of the metrics themselves shape the distribution, and they don’t fully represent what performance actually is.
In short, here’s the leap we made as a field:
Many performance outputs conform to a power law.
Therefore, human performance itself conforms to a power law.
Therefore, rewards should be allocated according to a power law.
The first is a description. The second is an assumption. The third is an extrapolation. The first one isn’t wrong, but we slide too easily into the second and third.
What is the meaning of performance?

The definition
John Campbell, the godfather of performance theory in I/O psychology, was unambiguous: Performance is defined as behavior under an individual’s control that contributes to organizational goals (Campbell, 1990; Campbell et al., 1993)3. Outcomes are important, but they are the consequences of performance, not performance itself. It may sound like hair-splitting. And who cares what a bunch of I/O psychologists think anyway?
(Have you ever tried to convince a sales leader that revenue is not performance? Here goes…)
This distinction serves three important, practical purposes:
Construct validity (i.e., meaning). In order to measure and make sense of performance, we need to distinguish it from its causes and effects. Inputs include ability and motivation. Outputs, like revenue, are a downstream result. Performance — what the person actually does — sits in between: in sales this looks like prospecting discipline, quality of discovery questions, objection handling, follow-up cadence, etc.
Controllability. To be accepted as legitimate, performance must be something we can reasonably attribute to a person. Behavior satisfies that condition, whereas outcomes often do not. Revenue depends not only on skill but also on territory, timing, lead flow, and market conditions, so a salesperson could display identical behaviors two quarters in a row and achieve very different outcomes.
Utility. If the goal of performance management is not just to measure but to improve, then behavior is useful in a way outcomes are not. “Sell more” isn’t helpful. But a salesperson can be coached on their qualification process and improve.
The distribution
If you haven’t rage-closed this article yet, here’s where it gets quite interesting. Even if we accept Campbell’s definition of performance as behavior, and behavior is normally distributed, we still have to explain why performance outputs are power-law distributed.
The answer is less mysterious than it sounds. Many performance outcomes are countable, bounded at zero, and open-ended at the top. Let’s borrow the example of home runs from O’Boyle & Aguinis. You can’t hit negative home runs, but you can hit a gazillion. Or, at least, Aaron Judge can.
(Have you ever tried to convince a baseball fan that home runs are not a great metric for baseball virtuosity? Here goes…)
Home runs are not the same as hitting performance itself. Hitting performance is the quality of the at-bat: plate discipline, pitch recognition, timing, bat speed, contact quality. The home run is the countable, downstream result of that performance, filtered through opportunity and chance.
Look at the distribution of home runs in the 2025 season for players with at least 100 plate appearances (i.e., those who played at least ~15% of regular-season games). Most players have just a few home runs, and a handful of players make up a large share of the total. That’s a power law, all right.
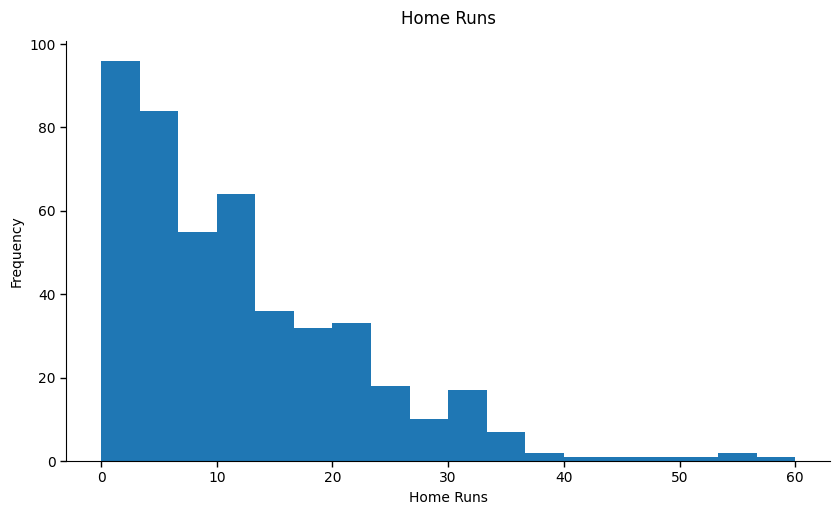
But the trouble with home runs is there’s a high exposure to opportunity. In other words, how many chances did a hitter have to hit a homer? For instance, over the course of a season, the number nine hitter in the lineup may expect over a hundred fewer at-bats than the leadoff hitter. We can control for that by looking at home runs per plate appearance. When we do, the distribution tightens and the tail shortens.
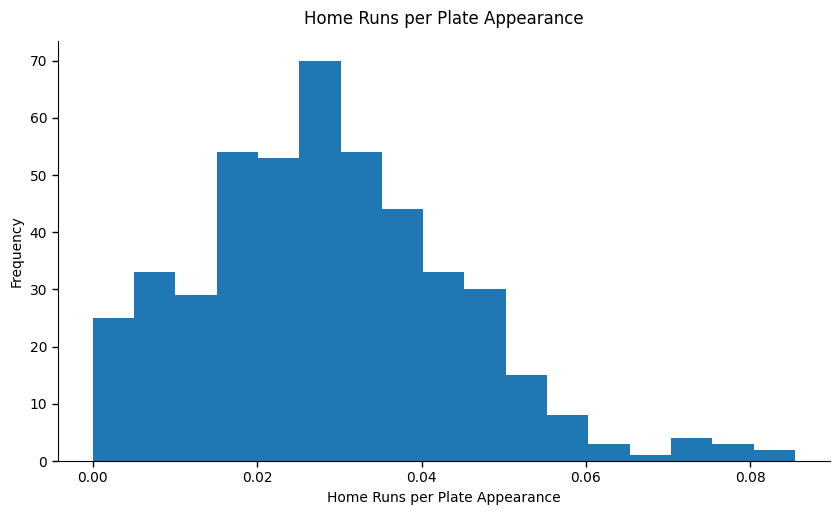
We can take it one step further. Even when you control for plate appearances, home runs still have a lot of noise — ballpark features, atmospheric conditions, just to name a few. Arguably a better proxy for hitting for power is slugging percentage (total number of bases divided by number of at-bats), and most modern baseball fans would consider OPS (on-base-plus-slugging percentage) as the best all-around hitting metric. (Even these are still more like outcomes than strictly behavior, but they’re a step closer than home runs.) These statistics help rule out some of the influence of chance and other external factors.
And look at the distributions of slugging percentage and OPS. Both pretty lovely normal curves.
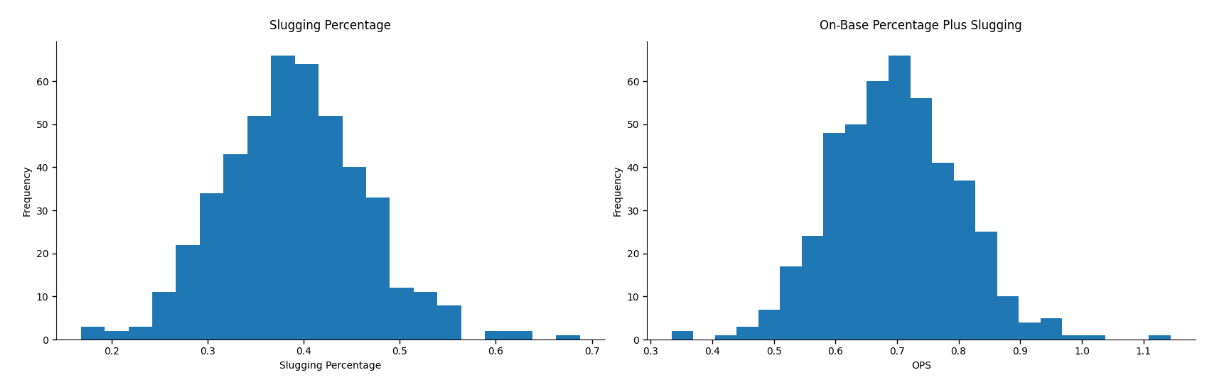
So what changed? Not human capability. Not the players. Not baseball. Only the way we measured the outcome. As we move from count stats to rate stats, we come closer to the underlying performance behavior, and the tail shortens. The shape of the distribution shifts with the structure of the metric, not the nature of performance itself.
Home runs are just one example. Just about every outcome from the O’Boyle & Aguinis paper shares the same structural features: cumulative, bounded at zero, unbounded at the top, and exposed to unequal opportunity. The skew they observed was real, but the overextension was taking that to mean the underlying human attribute was skewed too.
How misspecification creates misattribution
The same logic applies to many workplace outputs. Sales revenue, lines of code, tickets closed, customer calls, and bugs fixed are all cumulative, opportunity-shaped counts. They feel more objective than behavior because they are enumerable and proximal to business outcomes, but they can lend a false sense of precision and understanding of what actually drives quality and value.
If skew is shaped by measurement and opportunity, then it makes sense that it should vary systematically by role. The two most critical features are: how frequently the work converts behavior into measurable, comparable outcomes, and how clearly those outcomes can be attributed to one individual.
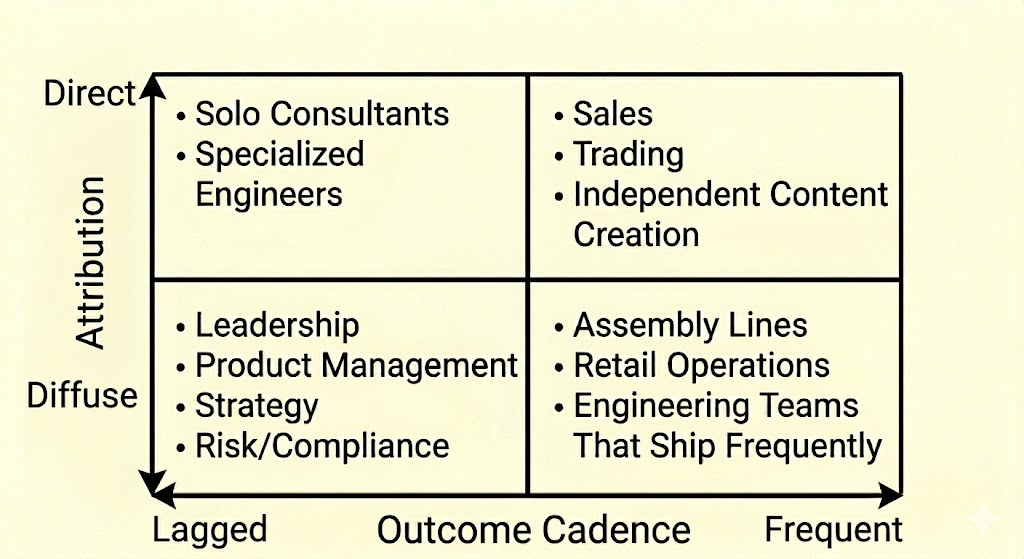
Extreme skew is most likely when small behavioral differences convert into many measurable “wins” that clearly belong to one person. If you remove either condition — delay outcomes or blur attribution — then the differences in output begin to reflect structure and opportunity as much as individual capability.
All that’s to say, performance in some roles (e.g., sales) may be relatively easier to describe using discrete outcomes, and others (e.g., leadership) may be difficult or impossible. But across that spectrum, performance is still behavior.
Follow the money
It’s one thing to observe skew in outputs. It’s another to engineer compensation systems around it. In recent years, many major companies have architected how they reward employees according to power-law principles, dramatically expanding bonus multipliers for top performers and compressing mid-tier rewards.
Compensation and performance systems are not mirror images of one another, but they are often deeply connected. If we believe performance is inherently power-law-distributed, then extreme differentiation is not only justified, it’s necessary. But that assumes we all agree on what pay is for.
Why do we pay people?
We use compensation for a number of different (and, at times, conflicting) purposes. Understanding each of those purposes can help us infer how power-law-style rewards play out.
Security & Stability. Pay provides predictability so people can focus on work rather than worry about survival. Tactically, this reduces cognitive load, increases psychological safety, and enables long-term planning. Power-law logic fits poorly here: extreme dispersion and volatility increases the perceived risk and shifts attention from contribution to competition and reward chasing.
Role Valuation. Pay reflects scope, responsibility and market value of skills. It anchors internal equity. Power-law reward structures, focused on individuals rather than roles, can undermine job architecture by favoring visible outcomes over structural contribution.
Attraction & Retention. Pay encourages people to join and stay at institutions. Power-law logic is wobbly here: Highly skewed reward systems may retain some top performers but risks alienating the capable majority who are also critical for collective performance.
Retrospective Recognition. Pay often serves to allocate rewards based on past contribution. This is where power-law practices fit most appropriately. Extreme dispersion of rewards feels consistent if outcomes are skewed and compensation is meant to reflect that impact retrospectively.
Motivation. We also use compensation to shape future behavior by signaling what matters. In roles with high attribution and frequent feedback (e.g., sales) tying rewards to outcomes can reinforce productive behaviors. (This is where we tend to see commissions.) But power-law practices are inherently backward-looking. And in roles where attribution is diffuse or outputs are lagged, it can distort priorities and promote short-term gaming.
Power-law-style rewards are really suited for only one of the many purposes of pay. Some companies may choose to optimize for that singular purpose. For all the other purposes, though, it’s inherently destabilizing.
What power law gets right
It would be easy to oversimplify the power-law view as a statistical or ideological misunderstanding or an excuse for inequity. That would be a mistake. There are at least three things it gets right.
Many outcomes in economic and work contexts — sales revenue, publications, home runs — are undeniably skewed. This reality is important for understanding value creation.
It’s not that everyone contributes equally or that differentiation is unjustified. People vary in persistence, judgment, and skill. And stars definitely exist: some people consistently outperform others, even after accounting for the situation or noise.
In certain roles — particularly those with direct individual attribution and frequent, countable outputs — strong differentiation in rewards may make sense.
The power law is a legitimate descriptive tool for understanding how value accumulates within systems. But skewed outcomes do not automatically imply equally skewed underlying ability. And even when extreme performance outcomes exist, that does not automatically settle the question of how incentives should be designed.
From distributions to decisions
How distribution becomes destiny
If the power-law claim were merely an academic debate, the implications wouldn’t be so weighty. When we adopt it as a de facto theory of performance and a basis for compensation strategy, though, we may gravely misallocate pay. Worse, we may treat performance as something we sit back and observe rather than something we actively build.
If high performance is an intrinsic property of a few exceptional people, there is little to learn and little to improve. We obsess over finding high performers, but we can’t create them. We can’t reproduce high performance because we don’t actually understand what generates outstanding results. Development surrenders to selection. Coaching surrenders to scouting.
It also changes how we invest in our talent. If we believe rewards should proportionately follow performance outputs, we may be tempted to ignore the broader system: the majority of employees, role design, feedback loops, training, collaboration. Many times, these conditions and systems are what makes the superstar possible in the first place.
Finally, these systems produce second-order effects as employees respond to incentive structures. Rewards concentrate around visible outcomes so risk-taking increases, internal competition intensifies, psychological safety tanks. It’s all the symptoms of a forced (normal) distribution of performance ratings, but on steroids. We may succeed in retaining some of our high performers, but we may also sow volatility, insecurity, and brittleness across the rest of the system.
What we choose to believe about performance
So, if it’s faulty and problematic, why do we believe and propagate this narrative? I think what makes the performance-as-power-law story so pesky is that it’s romantic. We prefer the mythos of the hero. It’s simpler to believe that, if we could only discover those diamonds in the rough, reward them, and retain them, we could build successful companies.
The truth is more complicated. Yes, we work hard to identify and hire people who have high capability. But then we must equip them, develop them, motivate them, recognize them, and build systems that sustain all of those processes.
The question I was asked in that meeting about the competency model of performance — why we should care what someone is good at, not just what they deliver — now feels less like a measurement issue and more like a philosophical one. We had different conceptualizations about what performance is, and why we measure it in the first place.
The dogma of modern business is that impact is all that matters. And, of course, it matters. But impact without understanding what created it is just chance, and we need to be able to recreate it.
Performance is not a power law. Some performance outputs are. Confusing the two warps how we measure, reward, and develop. This matters because the performance definition we choose will become the performance we create.
O’Boyle Jr, E., & Aguinis, H. (2012). The best and the rest: Revisiting the norm of normality of individual performance. Personnel Psychology, 65(1), 79-119.
Normal, symmetric distributions definitely aren’t the only distribution we observe in the real world and are probably too often assumed to be the default. Skewness is often naturally occurring, especially in processes related to time, growth, or amplification. My point is that we should scrutinize the shape of any latent human attribution, including performance criteria.
Campbell, J. P. (1990). Modeling the performance prediction problem in industrial and organizational psychology. In M. D. Dunnette & L. M. Hough (Eds.), Handbook of industrial and organizational psychology (Vol. 1, 2nd ed., pp. 687–732). Consulting Psychologists Press.
Campbell, J. P., McCloy, R. A., Oppler, S. H., & Sager, C. E. (1993). A theory of performance. In N. Schmitt & W. C. Borman (Eds.), Personnel selection in organizations (pp. 35–70). Jossey-Bass.
Great discussion of critical details that impact compensation levels. I'm amazed how much money companies spend on compensation without studying its impact on motivation. Particularly when it comes to deciding to pay some employees more than others based on often ill-defined or highly limited measures of performance. The article reminded me of this passage from the book Talent Tectonics:
"Pay differences often matter more than pay levels. If you want an employee’s attention, tell them you are increasing how much they are paid. If you really want their attention, tell them their coworkers are getting a bigger pay raise than them. Employees have strong reactions to even small differences in pay levels, especially if they do not meet their expectations . There is no such thing as a trivial difference in pay. Any difference will be seen as either motivating and equitable or insulting and unfair.
The term “pay dispersion” describes differences in compensation across employees working in the same job or organization. Zero pay dispersion, which means paying everyone the same, tends to be demotivating. It is particularly demotivating for high-performing employees who are sensitive to being recognized for their contributions to the organization . As pay dispersion increases, assuming pay differences are allocated based on performance, motivation tends to increase. But at some point, this starts to reverse. If pay dispersion becomes too great it creates feelings of anxiety that hurt performance. It can also create unhealthy competition which undermines people’s sense of teamwork and collective commitment. In sum, paying high-performing employees more than low performing employees is motivating, but not if the differences become too large. The challenge is figuring out the right level of pay dispersion for different types of compensation."
https://www.amazon.com/Talent-Tectonics-Navigating-Organizations-Reimagining/dp/1119885183
Excellent article! I have always been struggling with the bellcurve and I have written many times about it. The problem is not the distribution but that we link it to bonuses and rewards. We must separate them and then organisations wouldn’t care about the curve.